Kafka streaming in Python using Faust
Understanding the use-cases and how Faust works, as well as some of the more
nifty features.
Introduction
Since writing the last post, I have changed workplaces from Deliveroo to ComplyAdvantage. Here I’m working in one of the Media Insights teams that deals with processing articles from the web. This all sits in a mahoosive event pipeline which is linked by Kafka.
I say linked by Kafka - but that is more the aim, rather than the current design!
As such we are now experiment with a few tools available to us and the team made
a decision on using faust for this.
Annotations?!
Coming from Rubyland, seeing annotations on top of functions made me suspicious at first, but after reading a bit more about them, turns out they are just decorators or wrappers around your method. Annotations is the primary way that Faust works like.
This would look something like
@app.task
def my_async_task():
print("Doing work")
Lets get into Faust
So how would an app look like working with Faust? Well the common patter is
to use Faust for when we want to stream events, ie: we have an input Kafka
queue, we modify the message, we then push this on an output queue. This would
look something like this:
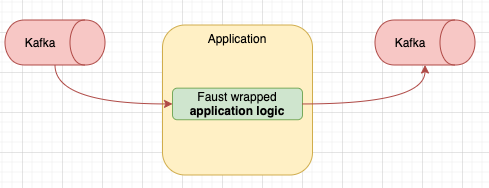
Faust makes this use-case very simple and is basically the bread and butter of its offering. The code to get something like that up and running is about 20LOC, even less if you remove the DLQ handling, but I find this to be actually quite important for almost any application.
app = faust.App(
app_config.name,
broker=f"{KAFKA_BROKER}",
)
input_topic = app.topic("input_topic", partitions=1)
dead_letter_topic = app.topic("dlq")
output_topic = app.topic("output_topic", partitons=3)
@app.agent(input_topic)
async def input_stream(stream):
async for doc in stream:
try:
result = BusinessLogic(doc).process
output_topic.send(result)
except FailedDocumentProcessing as error:
await dead_letter_topic.send(value=failed_doc)
raise error
finally:
yield None
How about some extras?
Some things come to mind fairly quickly like, how do I add monitoring to this? Faust comes built in with some sensors and you can add your own if you feel the default metrics don’t tell you enough. I’ve not experimented with that just yet - the default metrics are plenty to go on!
To do that you’d need to install Faust like this:
pip3 install faust[datadog]
and update your app initialization code like so:
from faust.sensors.datadog import DatadogMonitor
app = faust.App(
app_config.name,
broker=f"{KAFKA_BROKER}",
monitor=DatadogMonitor(
host=statsd_config.host, port=statsd_config.port, prefix=app_config.name
),
)
The default metrics provide a lot of information - so far the main one we used was committed vs read offsets, which are provided at partition level. Faust deals well with crashing services and offsets are not skipped which is great!
The fork
The main faust repository is not seeing any new development, however the community
is now supporting a fork here which
has quite a lot of improvements over the latest version of the original library.
One of the main gains we saw right off the bat was the performance - for our
particular use-case we saw almost a 2x speed increase going from the original
library to the fork.
Where it kind-of lacks
Even considering the fork and the development happening there, faust is
lacking in some areas. First of all - it would be around documentation - the
fork has not updated any documentation, and the main repo covers only really
the main use cases, if you are looking for anything non-standard - tough luck!
Such an example was around monitoring, which I had to dig from the community
Slack channel, which shouldn’t really be an off the beaten path type feature.
From what I’ve uncovered so far, there isn’t an easy way for us to control
options for the underlying aiokafka client, such as the polling frequency,
number of messages, byte sized pulled etc - which is a dis-advantage especially
when trying to performance tune this in production.
Writing tests for the library was definitely challenging and we hit a few
roadblocks, such as it requiring that yield None or else obscure error messages
would come up. I’ll do a bit more writing on this once we figure out how to
get any tests running using the fork, as that has proven very uncooperative.
Conclusion
We’ve still to deploy this into production at full-blown scale, and I’m sure there’ll be a fair few more learnings along the way - so definitely stay tuned for that - an update post will be happening for sure!